2026-12-17
SuperSegmentation: KeyPoint Detection and Description with Semantic Labeling for VSLAM
In Collaboration with Valeo Vision Systems (Automotive Intelligence Hardware Manufacurer) as Masters Project
Modern vision systems from self-driving cars to drones rely on a simple but powerful idea, to find reliable points in an image and track them over time.
These points might be corners of buildings, edges of traffic signs, or sharp lane markings. If we can detect and match these points across frames, we can estimate motion, build maps, and localize yourself in the world. This is inspired from humans and animals localization behavior. For example, we try to find ourselves in a place and memorize the map of the environment to navigate it based on risks and we know what we saw and where is what kind of object and the behavior attached to that object.
But here’s the catch for computer points as not all keypoints are equal. A point on a building facade is probably stable but a point on a moving car is not which we tend to understand based on more environmental knowledge. Most traditional systems treat all the points the same. But to make more intelligent system the program need to understand environment more on a deeper level.
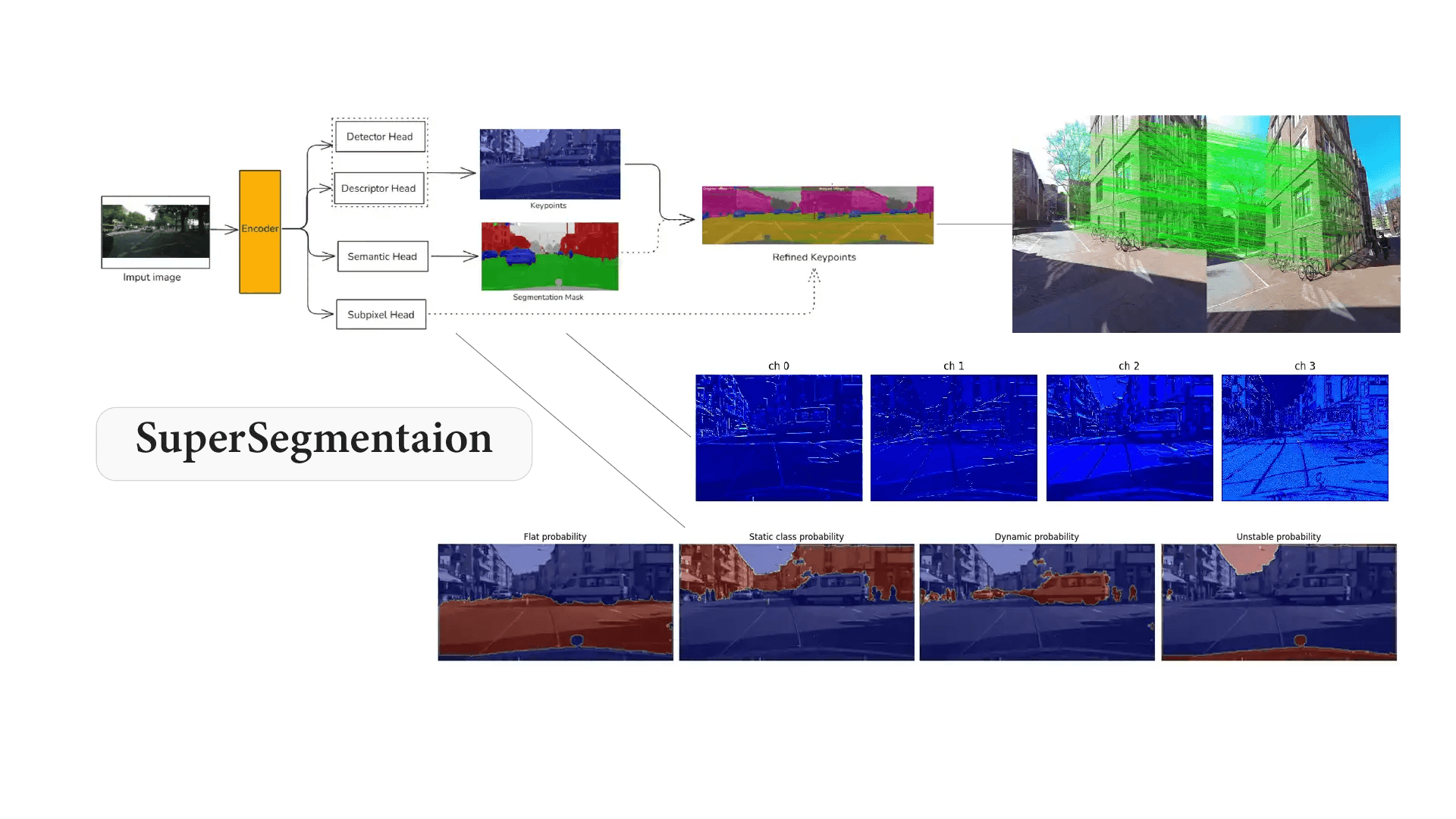
This is where SuperSegmentation algorithm comes in. It proposes a unified neural network that does something interesting: it detects keypoints, understands what they represent, and refines their location all at once.
The Traditional Divide: Geometry vs Semantics
In computer vision, two tasks often live in separate worlds. Keypoint systems (like SuperPoint-style models) focus on geometric consistency. Segmentation systems (like DeepLab-style networks) focus on understanding what the scene contains.
But in real-world driving scenes, especially in cities, this separation creates problems. Cars move. Pedestrians move. Trees sway. Shadows shift. Which are very dynamic and noisy data.
A Unified Architecture
SuperSegmentation combines geometry and semantics into a single unified model on geometrical data and behavioral information (semantics).
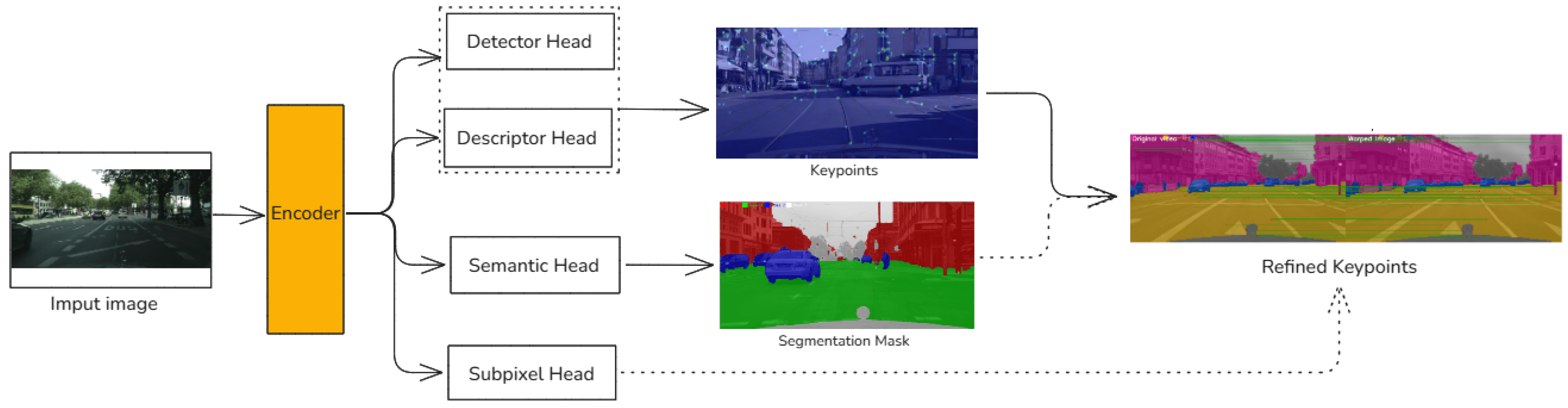
Instead of running separate networks, it uses one shared encoder (a convolutional backbone) and branches into four outputs:
- A keypoint detector (find interesting points)
- A descriptor head (describe each point for matching)
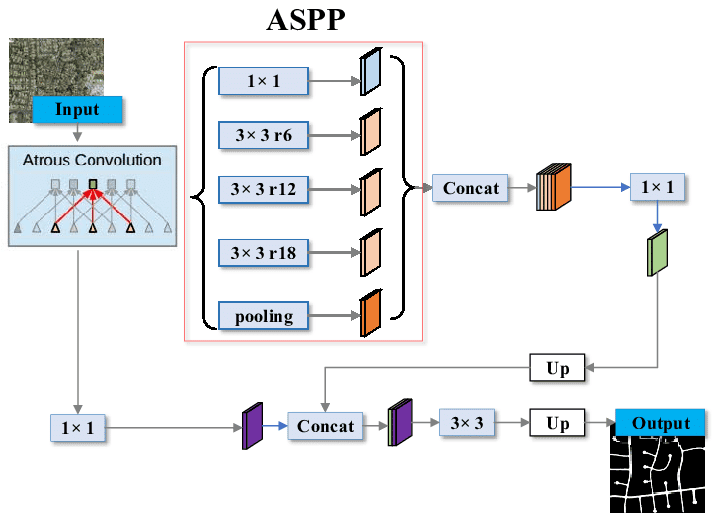
- A semantic segmentation head using ASSP (label the scene)
- A sub-pixel refinement head (improve localization precision)
Think of it as one brain with four functional parts which work independently and merge the results to gather informative data. Because all tasks share internal features, they influence each other. Geometry and semantics are no longer isolated they cooperate and shared.
Keypoints
Keypoints are distinctive landmarks in an image places that are likely to be found again under different viewpoints and light conditions. Here’s a depiction what matching looks like:

Each green line connects a keypoint in one image to its match in another. If enough matches are reliable, the system can estimate motion. But if many points lie on moving cars or pedestrians, those matches become misleading. That’s the instability SuperSegmentation tries to solve.
What the Network “Sees” Internally
Early layers behave like oriented edge detectors. They respond strongly to:
- Lane markings
- Building contours
- Object boundaries
- Texture transitions

Deeper layers combine these signals into more abstract representations. In SuperSegmentation, the same internal representation supports both geometric reasoning (keypoints) and semantic understanding (labels). That shared representation is central to the design.
The model is trained on the Cityscapes dataset, a large collection of urban driving scenes with pixel-level semantic labels and camera calibration data.

Instead of using all 30 classes directly, it groups them into four stability categories:
- Flat surfaces (roads, sidewalks)
- Static structures (buildings, poles, walls)
- Dynamic objects (cars, pedestrians, riders)
- Unstable/ambiguous regions (vegetation, sky)
Keypoints falling on dynamic or unstable regions can be filtered out before matching. This means the model doesn’t just find corners — it finds stable corners. Semantics becomes a geometric prior.
Sub-Pixel Precision
Most neural keypoint detectors operate on a fixed grid. That means detections snap to discrete locations. SuperSegmentation adds a refinement step. Instead of accepting the grid location as final, the model predicts a small offset. This allows each keypoint to move slightly and achieve more precise localization.
An analogy would be:
First, you mark the nearest square on graph paper.
Then, you adjust slightly to place the exact dot.
That small refinement reduces localization error is important for long-term tracking and mapping.
Training Strategy with Realistic Motion
Many keypoint systems train using strong artificial image distortions. But we take a more grounded approach. Using the camera intrinsics and extrinsics from Cityscapes to construct geometry-aware homographies and realistic transformations derived from actual camera motion.
Limitations and Future Directions
The evaluation is limited to Cityscapes. Metrics saturate under mild warps. Real-time performance is not fully benchmarked.
Future work could explore:
- Stronger motion scenarios
- Full SLAM integration
- Broader datasets (indoor, aerial, nighttime)
- Lightweight backbones for embedded deployment
Final Thoughts
SuperSegmentation doesn’t just add segmentation to keypoints. It reframes keypoints as semantically grounded entities. Each detected point is not just a geometric anchor it carries meaning and refined precision.
Shift from raw geometry to semantically informed geometry is essential for robust perception in dynamic environments. In complex urban scenes, understanding what something is helps determine whether it’s safe to trust. And that’s a small but meaningful step toward more reliable visual systems.
Full Paper: doi.org/10.20944/preprints202512.1410.v1